



The Blueprint - Part III: Training & Access Decisions
Taking an agile approach to implementing generative AI


Hello and welcome to part three of my Blueprint series where I’ll be covering the different training methods for generative AI and how we can tackle the challenges around data confidentiality, security, and fluidity. This post is longer than usual and goes into some technical areas (which I’ve simplified and kept to a minimum), but this is necessary to cover the ground that I want to cover and help readers understand the decisions to be made around training generative AI models on a businesses’ data.
In my previous article I covered the importance of knowledge management, which forms an essential part of any generative AI strategy. Knowledge is the foundation that any generative AI system will be built on so getting it right is vital. If you haven't read that yet, I encourage you to take a look here.
Generative AI Training & Data Access
As briefly covered in part two of The Blueprint series, there are broadly five options to consider when it comes to training generative AI models and giving them access to a businesses’ data. Below we go into each of them in more detail, explaining what they are and their pros and cons:
1. Pre-training
Pre-training involves pre-training a generative AI model from scratch on domain-specific data.
Pros:
Results in a highly specialised model that could outperform other training methods for specific tasks or domains.
The generative AI model will have a better understanding of the domain-specific nuances.
Cons:
Computationally expensive, time-consuming and has high environmental costs.
Requires large amounts of domain-specific data.
Requires specific deep learning technical expertise.
May make the generative AI model less effective at general tasks.
Knowledge can’t reference or be linked back to a source document.
Risk of overfitting if the domain-specific data is not diverse enough.
2. Fine-tuning
Fine-tuning involves re-training a pre-trained generative AI model with new domain-specific data.
Pros:
Computationally more efficient, less time-consuming and lower environmental costs than pre-training.
Tailors a pre-trained model to a specific task or domain.
Less domain-specific data required compared to pre-training.
Cons:
Requires specific deep learning technical expertise.
Knowledge can’t reference or be linked back to a source document.
Risk of overfitting to specific domain/tasks, leading to reduced performance of the generative AI model.
Risk of catastrophic forgetting, leading to reduced performance of the generative AI model.
Might require extensive hyperparameter tuning which can be time-consuming and resource intense.
3. Embedding
Embedding involves creating a mathematical representation of the knowledge that is stored in a separate vector database that the generative AI model can access.
Pros:
Computationally more efficient, faster and has less environmental impact than pre-training and fine-tuning.
Quick and easy to update.
Knowledge can reference or be linked back to a source document.
Cons:
Can be limited by the original generative AI model training.
It can be complex to create effective embeddings.
The embedded knowledge may not be fully utilised by the generative AI model.
4. Direct knowledge access
This involves storing knowledge in a traditional database and giving a generative AI model access via the ability to run SQL queries.
Pros:
Computationally efficient, and has the least environmental impact as no additional training is needed.
Good for numerical knowledge.
Knowledge can reference or be linked back to a source document.
Good for highly fluid data that needs to be updated regularly.
Access restrictions can be put in place for sensitive and confidential data.
Cons:
Adds complexity to the generative AI system and is not always as reliable as embedding.
Running SQL queries could slow down the response time of the model.
Not as good as embeddings for text-based knowledge.
Special care must be taken to prevent SQL injection attacks or unintentional data exposure.
5. Prompt engineering
Prompt engineering involves adding knowledge directly to the prompt and designing the prompt to guide the generative AI model towards the desired output.
Pros:
Computationally most efficient, faster and has the least environmental impact as no additional training is needed.
Good for text or image-based knowledge.
Knowledge can reference or be linked back to a source document.
Quick and straightforward way to adapt a generative aI model to new tasks.
Flexibility in controlling the generative AI model's behaviour.
Cons:
Requires careful crafting of prompts.
There is a limit to the amount of information that can be included in a prompt.
Not ideal for numerical knowledge.
May not always lead to desired output.
Can lead to inconsistent results for different prompt designs.
Next let’s look at the above techniques, their pros and cons and their suitability for different types of knowledge within a business.
Decisions, Decisions…
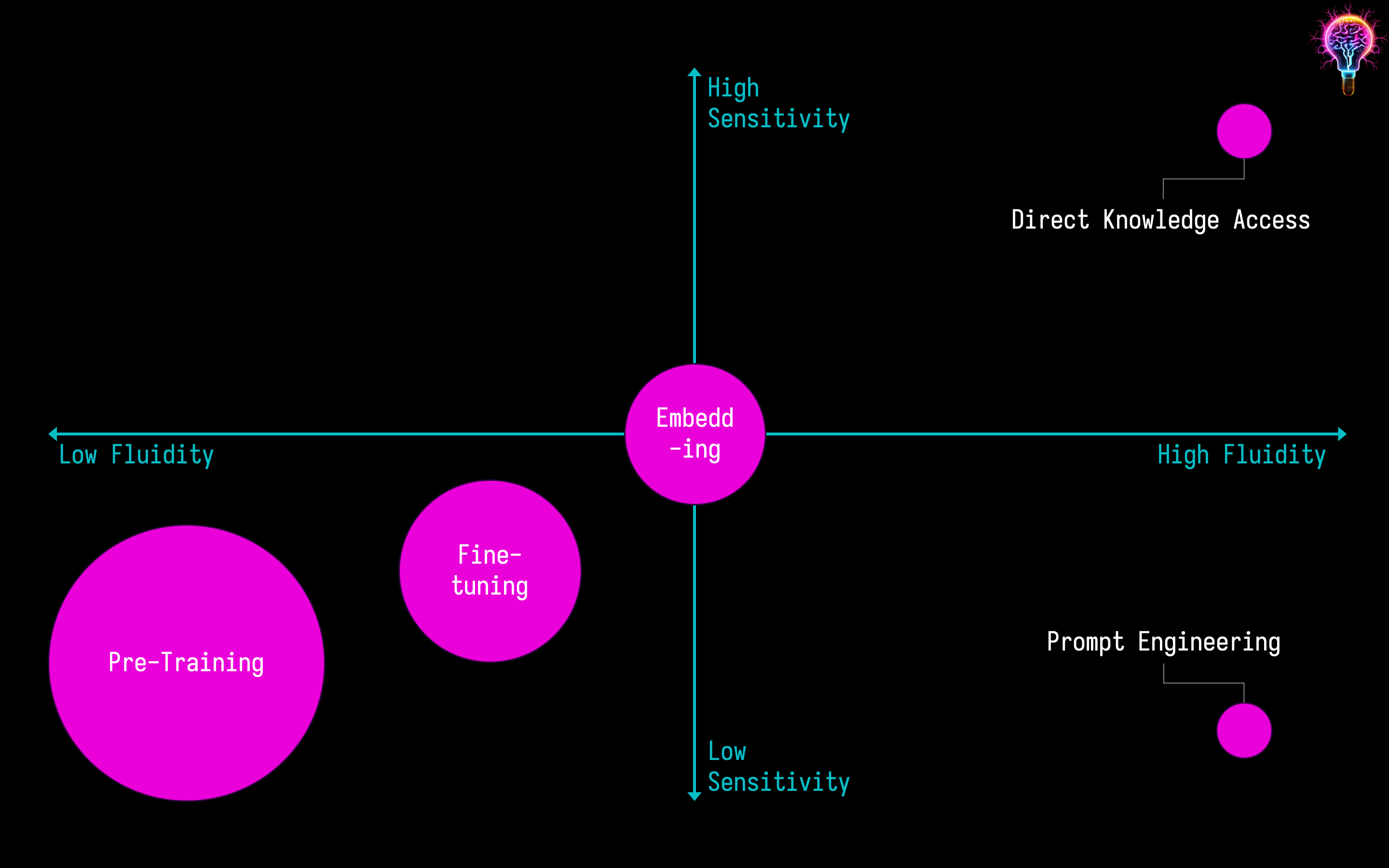
So, how do we decide which of these techniques to use? Let’s start from the bottom left:
Pre-training - I think we’re already at the point where the main generative AI models (ChatGPT, Claude, Bard etc.) are good enough at most tasks that it doesn’t make a lot of sense for many businesses to pre-train their own models. However, there are two exceptions - confidentiality and costs. If you want to pass highly confidential knowledge to a generative AI model and you’re unsure how safe that might be with one of the publicly available models then you should consider running your own in-house model. Also, if you have a high number of users and/or expect high usage of your generative AI tools then the costs of using publicly available generative AI models might start to be prohibitive - again it will make more sense to run an in-house model.
I’ll be going in to more details on in-house models when I cover the build/partner/buy decision later in The Blueprint series.
Fine-tuning - This is a really good option if you have specialised domain knowledge in your business/industry that is relatively static and doesn’t need updating frequently. However, fine tuning does need specialist and technical deep learning expertise, so won’t be for every organisation - it’s a big endeavour! Fine-tuning will be a great approach if you want a general purpose model in the business that has deep knowledge of you organisation and/or industry, but it will come with a price tag!
Embedding - I think this is probably the best middle ground for most generative AI use cases where you want to get the balance of giving the generative AI model quick an easy access to business knowledge that can be updated relatively frequently. Think overnight updates - more regular than that will probably get costly quite quickly. Embeddings are good for where you have knowledge that you want to update regularly as the embeddings can be overwritten individually. This isn’t something that can be easily done with pre-training or fine-tuning where you probably need to start from scratch each time to ensure that the knowledge is updated reliably. Embeddings are also good for written or visual knowledge where you want to be able to reference or link back to a source document.
Direct knowledge access - This is a great approach to take for numerical data that is stored in spreadsheets or databases. Essentially how it works is that the generative AI model will take your natural language query and execute it on the spreadsheet or database. This can also work for written or visual knowledge if it’s stored in a database as well. Direct knowledge access is also a good approach where you have confidential or sensitive data as you can restrict access based on the user of the generative AI tool/model, so useful for financial, employee and customer data. Sometimes the results aren’t always accurate as generative AI models aren’t 100% reliable in turning natural language queries into the correct database queries. GPT-4 is much better at this than GPT-3.5 was, but there is still room for improvement. One way this approach could be improved is to also fine-tune the generative AI model on the documentation and details of the databases you want it to access and provide example SQL queries to use for different use cases. This might be overkill though with the next generation of generative AI models likely to address any lingering reliability issues in this area.
Prompt engineering - This is by far the simplest and cost-effective approach to give a generative AI model access to your business knowledge if it is text based and can be accommodated in the prompt length restrictions that are currently in place with some models. These restrictions are likely to (effectively) disappear in the medium-term however as allowed prompt lengths expand to 1m tokens (c. 750k words, or the first five books in the Harry Potter series added together!). In fact Claude 2 from Anthropic already allows prompts of this size. The challenge with prompt engineering at the moment is that it has to be text-based. If using publicly available generative AI models, longer prompts also push up costs (as they’re based on the size of the prompt submitted) so isn’t always the best approach, depending on the use case.
Theory, meet Practice…
Let’s start putting all the theory covered above into practice by looking back at the different knowledge types covered in part two of The Blueprint series. To simplify this, let’s group some of these knowledge types together:
Emails & Chat channels - highly fluid and may contain sensitive/confidential data.
Written documents & Presentations - medium to low fluidity depending on the content and could also contain sensitive/confidential data.
Spreadsheets & Databases - highly likely to contain sensitive/confidential data and may have either highly fluid or low fluidity data.
Emails & Chat Channels
The idea of including emails and chat conversations in a business’ generative AI model is bound to be a controversial one. It will take quite a bit of cultural change before employees, customers and partners/suppliers would feel comfortable with the idea. However, there is a huge amount of valuable knowledge contained in emails and chat channels, so I strongly believe we need to find a way to include this in a business’ knowledge library.
The first thing that will need to be in place will be a clear usage policy for all employees, customers and suppliers. In the policy it should state that no personal information will be accessed by the generative AI model and that all sensitive information will be excluded. The policy should also emphasise that business communication platforms should not be used for personal communications. This is a relatively common policy, but is very rarely adhered to or enforced as the lines between our work and personal lives have blurred over time.
With a clear and sensible policy in place (so all stakeholders understand how generative AI will be used in this use case) we can then leverage generative AI’s strengths to summarise email and chat communications, removing any sensitive information. As emails/chats are very fluid I’d recommend that this is run as a nightly process with the summarisations then turned into embeddings that the generative AI model can access.
There is also important metadata that should be captured and included with the summarisations, such as subject and date of communication. This will allow different email and chat threads to be linked together by the generative AI model. It would also be useful to capture the sender and recipient but this might be a step too far. To ensure no personal data is included the names/email addresses could be replaced with employee/supplier/customer IDs that only certain teams/individuals have access to.
Written documents & presentations
Compared to emails and chats, this one should be a (relative) breeze! There are two important area to address, and they’re confidentiality and version control. There will be documents in a business that are confidential and shouldn’t be included in a generative AI model and there will be documents that would be incredibly useful to include. A simple way to manage this will be to have a specific location and/or naming convention for any document that shouldn’t be included. Best practice would be for any confidential document to be marked as such anyway, so we can then design the generative AI training around that.
Once the confidentiality challenge is taken care of, the important thing for any documents included in a generative AI model is that you’re able to source and reference the information if the model is using it. This will allow users to fact check and also then explore the wider context of the answer they have been given by the model. The way to achieve this will again be with embeddings and metadata that should be captured and included when the embeddings are created. And this is where you can handle version control as well. When a new version of a document is created then you can choose to either overwrite the existing embedding or you can create a new embedding with the new version number in the metadata. This will allow you to keep track of which version the generative AI model is accessing. My head says that overwriting the embedding would be the best approach, as there’s a change the model accesses the wrong version of the embedding but you could build in logic to only ever reference the highest version number.
Similar to email and chat channels, I’d recommend running an overnight embedding process so that your generative AI model has access to the latest information the next day.
Spreadsheets & databases
Unlike most artificial intelligence technology, generative AI doesn’t have a great time with numerical data as it’s built mostly around text, images, video etc. What it can do well though is code, and specifically it can write pretty good SQL queries. So for any numerical knowledge in a business, it’s best to load it into a simple database that a generative AI model can then access and turn natural language queries into SQL queries. The added benefit of having all your numerical knowledge in a database is that you can then more effectively manage the security and access control around the knowledge but linking permissions back to the individual user of the generative AI model.
As a quick aside, I’m also really interested in how generative AI models are getting good at working with APIs in general. There’s a huge opportunity to open APIs up to natural language queries and make the data/services they provide more accessible to the general population!
So with spreadsheets and databases, I don’t think it makes sense to look at fine-tuning, or embeddings. I’d go for direct access with the generative AI model retrieving what it needs from the database using SQL.
Summary
In this article I’ve covered the training and access decisions that a business would typically need to make as part of a generative AI strategy. This is the next important step after determining what knowledge you’d want a generative AI model to be trained on or have access to.
In the next article in The Blueprint series, I’ll be looking at the ideal business technology stack for creating and managing all the different knowledge I’ve discussed above and how that can then connect in to a generative AI technology stack.
"The future is already here, it's just not evenly distributed."
William Gibson
This article was researched and written with help from ChatGPT, but was lovingly reviewed, edited and fine-tuned by a human.