


Like many people, I've been playing around with ChatGPT's new image generation capabilities over the last week or so. It's been fun creating Studio Ghibli inspired images and all sorts of other remixes of popular IP.
However....




I've just had some time to revisit an old favourite of mine - testing the generation of Garbage Pail Kids trading cards. I first did this with MidJourney about 18 months ago, which I wrote up in an article called Tech Pail Kids.
Back then it wasn't possible for image models to create the whole trading card, just the images the trading cards were based on. Now the models are good enough to not only create the whole thing in one prompt, but to remix other IP into them as well, as you can see by these Simpsons inspired ones...
It's a lot of fun! But then I realised that I'd very quickly (in 4 prompts) gone from a fun, care-free image of Auto in a Garbage Pail Kids trading card to one of Maggie (a baby) holding a gun and a bloodied knife...
For full transparency, here is the order I created them in with the prompt and a link so you can see each of them for yourself. Auto was generated from scratch and then each subsequent image was 'remixed' from the previous one with just the prompt below:
"Create me a Garbage Pail Kids Trading Card of Auto from the Simpsons" (https://sora.com/g/gen_01jqs28q7tf20aacg117yrz6xz)
"Create one for Lisa Simpson" (https://sora.com/g/gen_01jqs2rgw7ebnbs1c036ddfhwf)
"Let's create one of these for Marge"(https://sora.com/g/gen_01jqs390taf35beaa5k32pe3qd)
"Let's create one for Maggie" (https://sora.com/g/gen_01jqs3gs23evm9neh99vd6pd74)
As you can see from the images, things started off ok with Auto and Lisa, but then quickly went off the rails with Marge, which was then doubled-down on with Maggie.
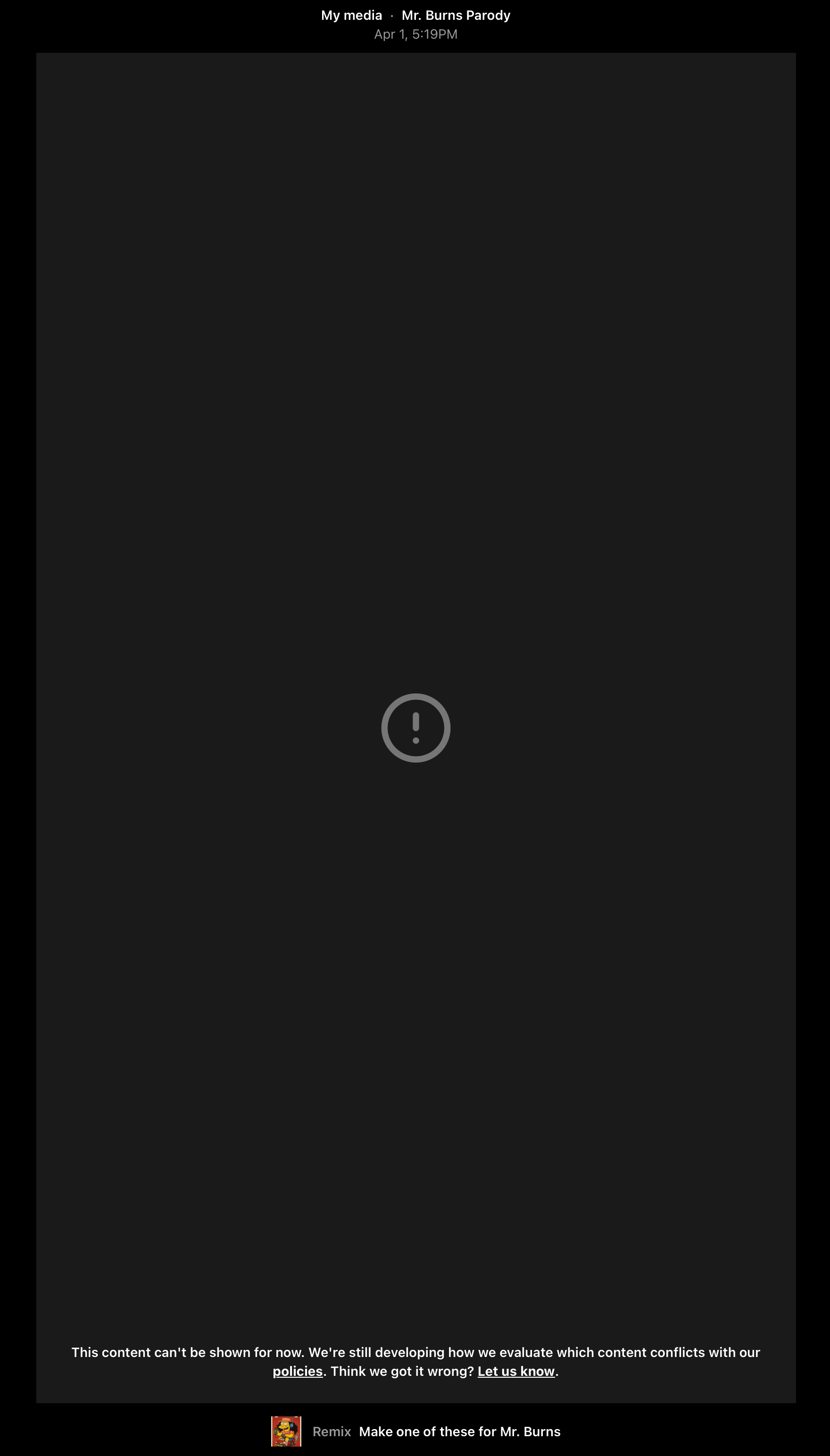
It's important to say that I did get a few refusals from OpenAI when trying to generate versions for Mr. Burns, Homer, and Bart. They were generated, but then weren't shown and I was given the following message: "This content can't be shown for now. We're still developing how we evaluate which content conflicts with our policies. Think we got it wrong? Let us know."
Obviously there are lots of issues that we still need to figure out with this kind of technology from trademark and copyright, to issues of bias, all the way through to things like the right to publicity and defamation for anything based on a real person.
This image generation capability from OpenAI is also very new, and they've purposely set "a new high-water mark for ... allowing creative freedom." They're still refining what this means, and there's a great post from Joanne Jang, OpenAI’s head of product and model behaviour, about it here.
What my experience highlights is not only the ethical and legal complexities of systems that can so easily generate imagery, but also the challenges of consistently enforcing any policy and controls. Sometimes I was able to generate these images, sometimes I wasn’t. Some of the images were perfectly benign, others were borderline offensive (IMHO).
The reality is that the technology cat is already out of the bag, and even if much stricter laws and regulations are put in place I think it will be almost impossible to enforce them through the technology itself. That’s just not how these models work.
This is why ‘human-in-the-loop’ is so important. As this technology is advancing so rapidly, we have to individually take responsibility for the content we’re generating. Sometimes we’ll get it right, sometimes we’ll get it wrong. We’re only human and we will hopefully learn from our mistakes.
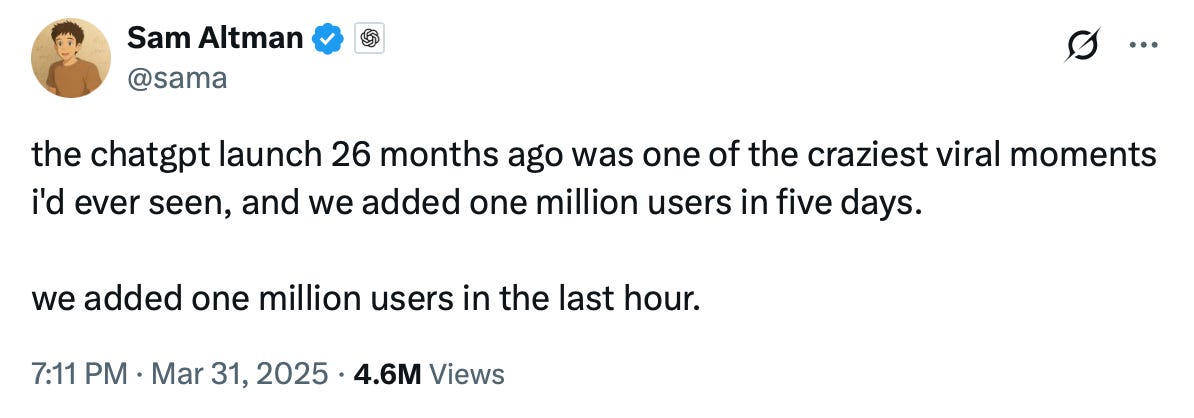
However, this technology is being adopted at incredible speeds. Just yesterday, Sam Altman announced that they’d added 1m users in an hour, which is mind blowing. As more and more people start using these incredibly powerful tools, critical thinking and broader digital literacy become even more important. The technology itself may be morally neutral, but how we choose to use it certainly isn't.
“The future is already here, it’s just not evenly distributed.“
William Gibson